InTowards AIbyAla Falaki, PhDHydraSum: Disentangling Stylistic Features in Text Summarization (Paper Review/Described)Is it possible to train a model with transformer architecture to learn generating summaries with different styles?May 26, 2022May 26, 2022
InTowards AIbyAla Falaki, PhDBRIO: Bringing Order to Abstractive Summarization (Paper Review/Described)A new state-of-the-art result for the text summarization task on both CNN/DM and XSum datasets. It uses contrastive learning to rank the…Apr 25, 2022Apr 25, 2022
InTowards AIbyAla Falaki, PhDSimCLS: A Simple Framework for Contrastive Learning of Abstractive Summarization (Review/Explained)Explain the paper that currently holds the state-of-the-art result in text abstractive text summarization.Mar 14, 2022Mar 14, 2022
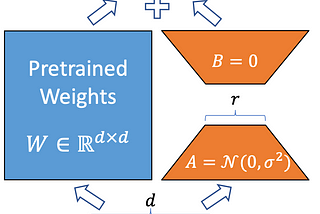
Ala Falaki, PhD1000x Smaller GPT-3/2? LoRA: Low-Rank Adaptation of Large Language ModelsIs it possible to use large models such as GPT-3 (175B parameters) for downstream tasks with training only 37M parameters and outperform…Jun 19, 20211Jun 19, 20211
InTowards AIbyAla Falaki, PhDOpenAI Threw Resources at Book Summarization Task (Paper Review/Explained)Explain and Review the questionable “Recursively Summarizing Books with Human Feedback” paper and its effectiveness.Oct 8, 20211Oct 8, 20211